Open Access
Research Article
Max Screen
ISSN: 2455-765X
Copyright: © 2018 Lawal HB. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Related article at Pubmed, Google Scholar
We have presented in this paper alternative computation to arrive at results obtained in Lindsey and Altham (1998) on the use of the beta-binomial, the double binomial and the multiplicative binomial models to the Human Sex Ratio data. Our procedure estimates fewer parameters and thus the goodness-of-fit test statistics computed here are based on more d.f. The results obtained, using SAS PROC NLMIXED agree with those presented in the Lindsey et al. paper. Further, we extend the study to two additional distributions, namely, the Com-Poisson binomial and the correlated binomial distributions. Our results give the estimated probabilities under all the models considered here and we are able to compute the success probability under the multiplicative binomial model for the global data.
Keywords: Beta-binomial; Multiplicative Binomial; Double Binomial; Com-Poisson; Correlated Binomial; Success Probability
Lindsey and Altham (1998) re-analyzed the human sex ratio data collected by Geissler (1889) [1,2]. The data relate to the distribution of the sexes of children in families in Saxony during 1876-1885. A reproduction of the data is also presented in Edwards (1958) for distribution of boys of size 2-13 [3]. We have in this paper further provided a presentation of the data arranged by family size and corresponding frequencies. The data has been arranged so that for instance the data used by Sokal and Rohlf (1969), p.80 can now be found in row F12 for n=12. Similarly, that used by Fisher (1958) for a family size of n=8 can be found in row F08 for n=8 [4]. The number of children in each family therefore varies from 1 to 12, and is denoted by n in this paper. A detailed description of the data can be found in Edwards (1958) [3].
Questions of interest from previous studies are succinctly stated in Lindsey and Altham and include ’whether the probability that the child is a boy varies among families and whether it can vary over time within a family’. As argued in Lindsey and Altham, because the Geissler study results in an aggregated data, both questions may not be distinguishable and that they will inherently manifest themselves as overdispersion with respect to the binomial model. As presented in Lindsey and Altham, we will look at whether variability changes with family size.
In this study, we shall compare the behaviors of the binomial model (BN) with those of five other models, namely, the beta-binomial (BB) Skellam (1948); the multiplicative binomial (MBM) Altham (1978), Elamir (2013); the Com-Poisson Binomial (CPM) Borges et al. (2013), the double binomial (DBM) Lindsey and Altham (1995) and the correlated binomial Kupper and Haseman (1978) distributions [5-10].
Lindsey & Altham (1998), employed the beta-binomial, the multiplicative and the double binomial models as overdispersed models for the data in Table 1. In their paper, the forms of the multiplicative and double binomial models employed were characterized with intractable normalizing constants c(n,ψ) and c(n,π) respectively. Consequently, these models were implemented in Lindsey and Altham (1998) by utilizing a generalized linear model with a Poisson distribution and log link to the frequency data. This approach has earlier being similarly employed in Lindsey and Altham (1995) [1,9]. This approach, which employs joint sufficient statistics in both distributions was proposed in Lindsey and Mersch (1992) [11]. Thus, both distributions are fitted using a Poisson regression model having sufficient statistics from both distributions as explanatory variables with the frequencies being the mean dependent variables. For the Double binomial model (DBM), the sufficient statistics are ylog(y) and (n-y)log(n-y). Similar sufficient statistics for the multiplicative binomial model (MBM) are y and y(n-y)with the offset being z=log(n y) for both models. However, this approach is not efficient. Their approach fits the following model:
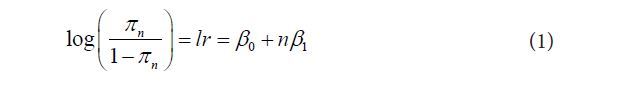
resulting in,πn 1/(1exp(-lr)). Here, we see that the logit of the probability of “success” is a linear function of family size n. This approach is very similar to those employed in Lefkopoulou et al. (1989), where,
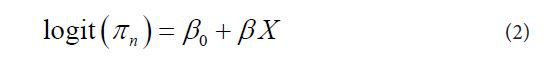
The model in (1) is employed to model the probability of success for each of the distributions considered in this study, the exception being the Com-Poisson binomial model (CPM) described later in this paper [12].
Further, the dispersion parameters for each of the models are expressed as exp(a0+na1),n=2,3,....12. The exception here being the correlated binomial (CBM) and the Com-Poisson binomial, because the dispersion parameters θi and vi in both models can take positive and negative values.
The formulation of the success probability model and the dispersion parameter models are as formulated in Lindsey and Altham (1998) [1]. However, because of the joint sufficient statistics’ approach employed in their paper, each model so formulated is based on thirteen parameters. In this study, the same models will be fitted, but with only four parameters, giving us more degrees of freedom for inference. Our models generate perfectly, the results in Lindsey and Altham (1998), even though we have employed only four parameters for each distribution [1]. We also examine the following variations of these models, for n=2,3,....12 family sizes.
(a) The model that assumes that for all n, we have constant probability of ’success’ and constant dispersion parameter (ϕ is that for the double binomial for instance). That is,
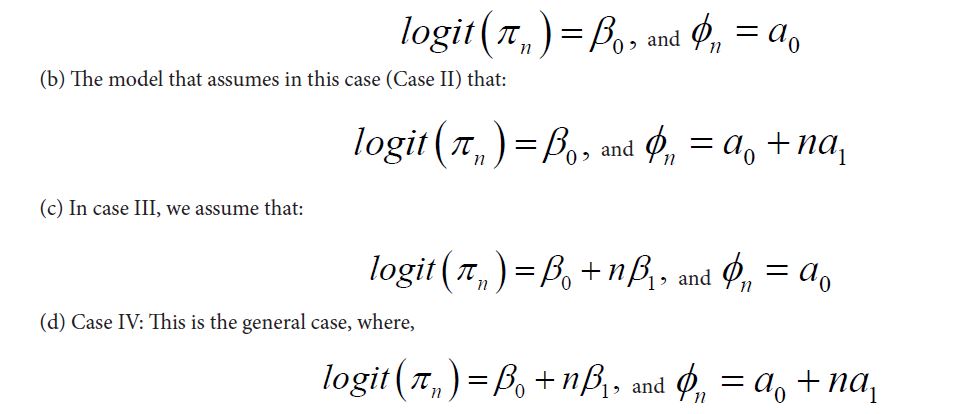
Since the data is binary, a binomial model applied to the entire data (excluding family size of one) gives an estimated probability of males ’success’ to be 0.5150. The dispersion parameter estimate from this model (X2/d.f.) is 9117.9513 which is very much greater than 1, indicating a very strong over-dispersion in the data. Thus, the binomial model would not fit these data and we thus consider in the following sections, the five over-dispersed probability distributions employed in this study.
Lovison (1998) proposed an alternative form of the two-parameter exponential family generalization of the binomial distribution first introduced by Altham (1978) which itself was based on the original Cox (1978) representation as [6,13,14]:
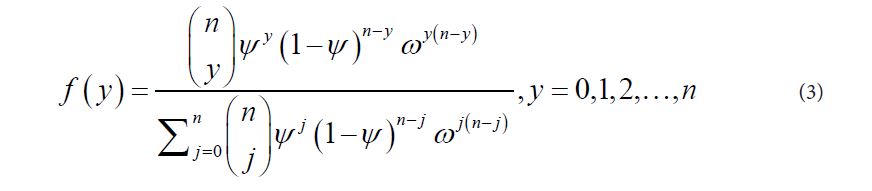
Where 0 < ψ < 1 and ω > 0. When ω =1 the distribution reduces to the binomial with π =ψ . If ω=1, ,n→∞ and 0ψ→, then nψ→μ and the MBD reduces to Poisson (μ).
Elamir (2013) presented an elegant characteristics of the multiplicative binomial distribution including its four central moments. His treatment includes generation of random data from the distribution as well as the likelihood profiles and several examples.
Following Elamir (2013), the probability π of success for the Bernoulli trial, can be computed from the following expression in (4) as [7]:
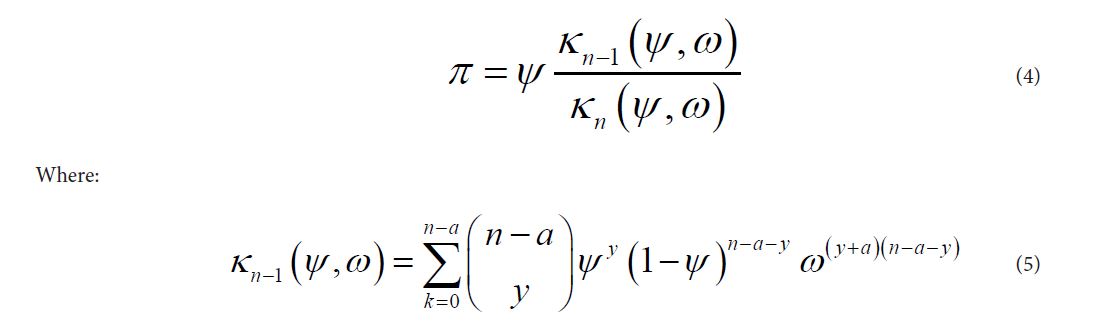
with π defined as in (4), ψ therefore can be defined as the probability of success weighted by the intra-units association measure ω which measures the dependence among the binary responses of the n units. Thus if ω=1, then π=ψ and we have independence among the units. However, if 1 ω≠, then, πψ≠and the units are not independent.
The mean and variance of the MBM are given respectively as:
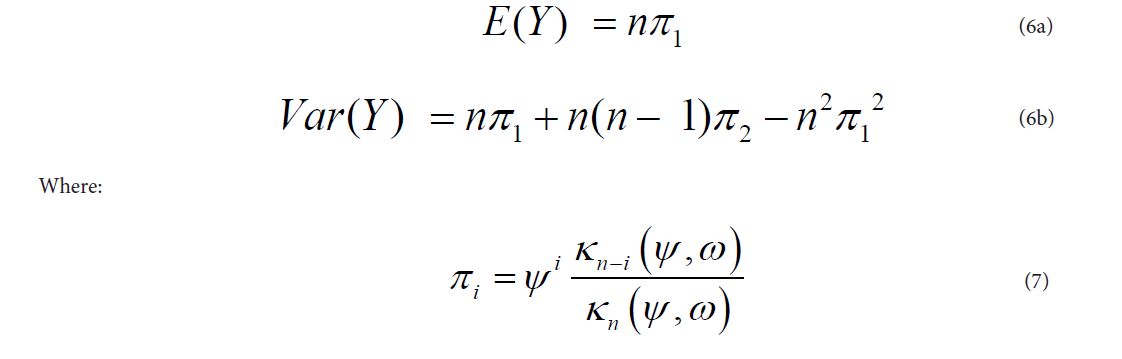
The Beta-Binomial distribution Skellam (1948) has the probability distribution den-sity function [5]:
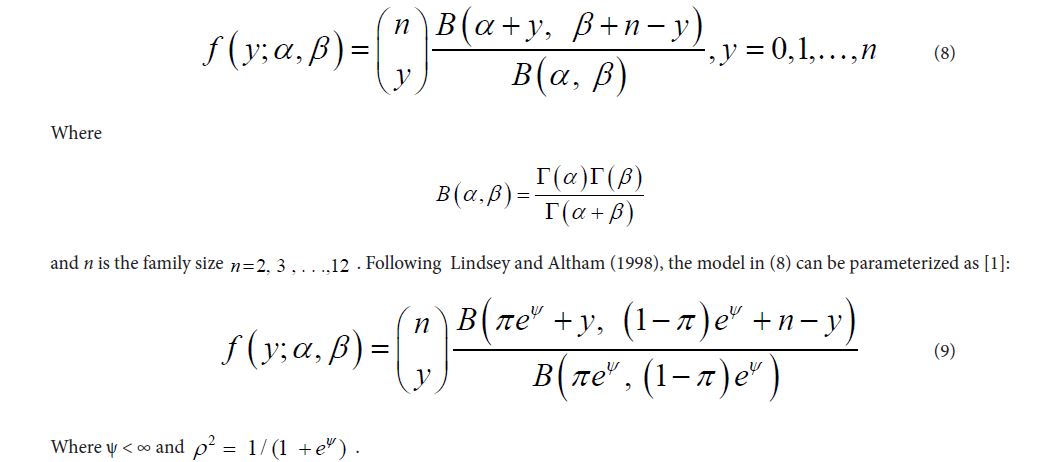
The probability density function for the Com-Poisson Binomial distribution is given by:
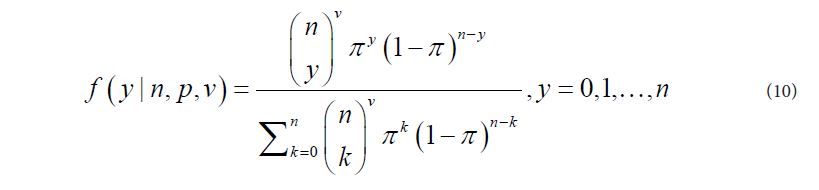
With π€ (0,1) and v€ R . If ν = 1, the model reduces to the binomial distribution and values of v>1 indicate underdispersion, while values of v< 1 similarly indicate overdispersion with respect to the binomial distribution
An approximation to the CPB distribution in the limit n → ∞ and with λ = nν p is given in Shmueli et al. (2005) [15]. Following Borges et al. (2013), if we let θn be defined as [8]:
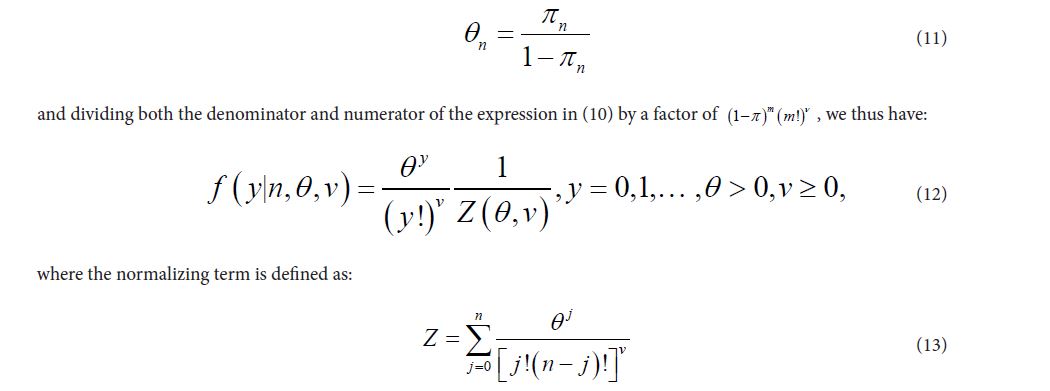
The various properties of the CPB or the Com-Poisson have been presented in various papers Borges et al. (2013), Shmueli et al. (2005), and Kadane et al. (2006) applied the CPB to the number of killings in rural Norway [8,15,16]. In this study, with θ defined as θn=α0+nα1 for the family sizes, then the estimated probabilities are obtained as πn=ˆθn/1+θn.
In Feirer et al. (2013), the double binomial distribution was presented, having the pdf form [17]:
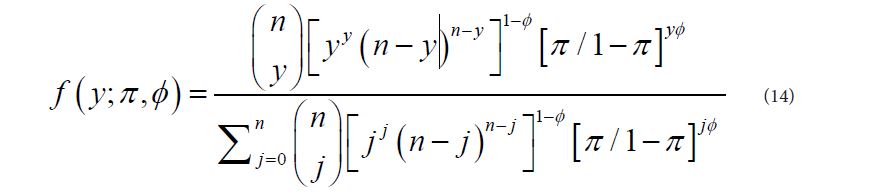
For y = 0, 1, . . . , n, and following Feirer et al. (2013), its log-likelihood is presented in (16c).
A fetal death model proposed by Kupper and Haseman (1978), which is a generalization of the binomial model has the form [10]:
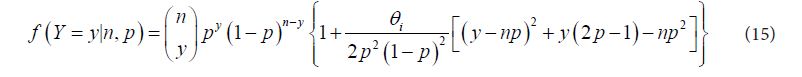
In (15), θi is the covariance between any two responses within the same litter. The model above allows for negative intra-litter correlation, as distinct from the other models considered that only allow for positive dispersion parameters.
Because of the bounds on θi for this model, it is modeled here as θi = b0 + ni bi,i =2, 3, · · · ,1 2 rather than taking its exponent.
For a single observation, the log-likelihoods for the multiplicative binomial, beta- binomial, double binomial, the Com-Poisson binomial, and the correlated binomial are displayed in expressions (16a) to (16e) respectively.
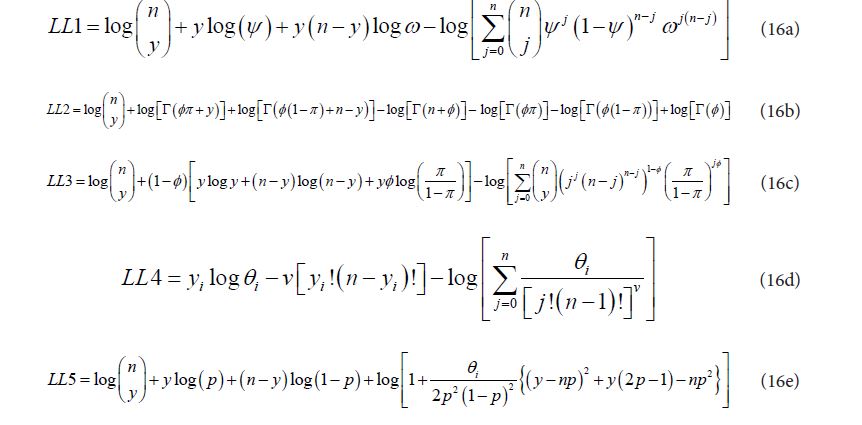
Maximum-likelihood estimations of the above models are carried out with PROC NLMIXED in SAS, which minimizes the function -LL(y,Θ) over the parameter space numerically. The default integral approximations of the marginal likelihood in PROC NLMIXED is the Adaptive Gaussian Quadrature as defined in Pinheiro and Bates (1995) and the optimization algorithm adopted in this study is the Newton-Raphson iterative procedure (NEWRAP). Convergence is often a major problem here and the choice of starting values is very crucial [18]. For each of the cases considered here, we are able to achieve rapid convergence for all the distributions.
As discussed earlier, following Lindsey & Altham, we model the probability, πn as a function of family size n, viz logit(πn)=β0+nβ1 Similarly, the corresponding dispersion parameters are also modeled as: log(ω)=α0+nα1. Thus, for the multiplicative binomial, for instance,ω=exp(lp) , and both are functions of family size n. Further, for each model, we are estimating only four parameters where for instance, for the beta-binomial model for example, we are estimating only {α0,α1,β0,β1} as compared to 13 parameters that were estimated in Lindsey and Altham paper.
In Table 2 are presented the parameter estimates and their standard errors (in parentheses) under the five models for cases I to IV [19-21]. For the full models (Case IV), we see that only four parameters are estimated for each model in contrast to Lindsey and Altham (1998) thirteen parameters [1].
The -2LL values for the beta-binomial in case IV were 2174100.8 but we have reported this simply as 4100.8. That is, we are reporting only the last four digits. In each case, the values of 217 had been truncated for brevity only. What is obvious from Table 2, is that, irrespective of the model being employed, the data is better modeled with a variable dispersion parameter, that is, cases II and IV. In other words, models that assume uniform dispersion parameter (within a given distribution here) are not satisfactory for the data. The -2LL and goodness-of-fit test statistics, the Pearson’s
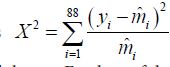 and the likelihood-ratio test
and the likelihood-ratio test
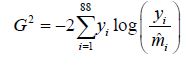 all indicate that the models in cases II and IV are much better. Further, of the two parsimonious models in cases II and IV, model IV which is equivalent to Lindsay and Altham (1998) model is most parsimonious. For instance, for the beta-binomial model, the difference in G2 for the two models is 125.5495 − 107.7504 =17.7991 on 1 d.f., (G2 rather than X2 is used here because of its partitioning property over X2) which clearly indicates that β1 is important in the model, given that α0, α1 and β0 are already in the model. Consequently, we would focus our attention on models in case IV for all the distributions.
all indicate that the models in cases II and IV are much better. Further, of the two parsimonious models in cases II and IV, model IV which is equivalent to Lindsay and Altham (1998) model is most parsimonious. For instance, for the beta-binomial model, the difference in G2 for the two models is 125.5495 − 107.7504 =17.7991 on 1 d.f., (G2 rather than X2 is used here because of its partitioning property over X2) which clearly indicates that β1 is important in the model, given that α0, α1 and β0 are already in the model. Consequently, we would focus our attention on models in case IV for all the distributions.
For these five models, the best three models in case IV that best fit our data are in the order (a) Multiplicative binomial, (b) The beta-binomial and (c) the Com-Poisson binomial distributions. However, we present in Table 3, the estimated probabilities for each family size under each of these models.
In Table 3 are presented the estimated probabilities from each of these models. We present the computation of the first probabilities for family size n=6 as an example. For the beta-binomial, this equal πi=1/[1+exp(-0.0498-0.0018*6)]= 0.5151.
Similarly, under the multiplicative binomial model,ψ^6=1/[1+exp(-0.05219-(0.000864×6))]=0.51434.
However, this is not the required probability. The required probability,π16 can be computed using (7) as:
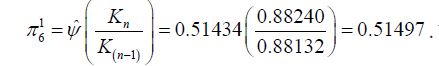
Similarly, the estimated π1n obtained (first probability) under the multiplicative binomial model are very consistent with those from the BB. The questions posed in Linsey and Altham regarding the good fit of the multiplicative binomial model, namely:
(a) Does it (i.e. the multiplicative model) have some biological significance similar to the idea for the beta-binomial model of the Bernoulli probability varying across the population according to a beta distribution?
(b) Can more be said about the parameters than the empirical statement that the probability and dispersion both increase with family size?
Based on our ability to now be able to compute the central moments of the multiplicative Binomial model (Elamir (2013)), the ψ in our model specification in (3) is not necessarily equivalent to the desired πn, our ability to now be able to compute the πin,i=1,2,3,4 and in particular, the case when i = 1 which corresponds to our Bernoulli or BB parameter πn from expressions in (7) answers the question poised in (a) [7]. Thus, π1 is considered to be the ’probability of success while ψ is the probability of success weighted by the intra-association measure ω given the dependence among the binary responses of the units.
As to the second question, the results of ˆωn in Table 5, indicate that ω^n<1,∀i and decreases as the family size increases. Thus, while ω^2=0.99050, that for ω^12=0.97227. These indicate decreasing variability as family size increases. On the other hand, for the beta-binomial, both probability and dispersion parameter increase with family size. For values of n small, estimates of ω are very close to 1, indicating closeness to being independent observations and can be appropriately modeled with the binomial distribution.
Also, in Table 5, the computed dispersion parameters for the double binomial, ϕ and the Com-Poisson binomial, ν, indicate decreasing dispersion parameters as the family size increases. For both the beta and correlated binomial, the dispersion parameters however, increase with family size.
We present in this section results of goodness-of-fit tests for all the models considered in this study. From the global model for each distribution, and a given estimated set of parameters, the probabilities of Y=0,1 , . . . ,n and corresponding expected values are computed from the log-likelihood equations. For example, for the multiplicative model, this is, for a given family size n, the LL1 is as presented earlier in (16a). Hence, the corresponding probabilities are computed for Y=0,1 , . . . ,n as P^Y=P(Y=y)=exp(LL1) and the corresponding expected values are ˆmy=Np^y, where N for the family of size 12 for instance is 6115. We give in Table 6, the computed probabilities, the expected values, and contributions to the likelihood-ratio test statistic G2 and Pearson’s X2 for the multiplicative binomial for n=2,3,4and n=12. Here, G2 and X2 are defined as
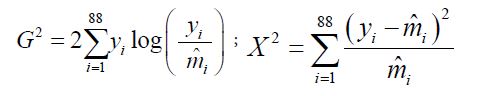
where ˆmi=Np^i= are the expected values as defined above for each family size n .
From Table 6, our computations for the G2 and X2 exclude the case when n =1, that is, family size of 1. Thus, we have the computations over 88 observations only. Note that for each n, the cumulative sum of probabilities (designated here by Σpy) sums to 1 for each family size n. We are re-assured that for a given n these probabilities sum to one. We have presented the results for n=2,3,4 and n=12 only. The sample sizes for n = 2, 3, 4, 12 are respectively 179,892; 148,903; 120,137; and 6,115. The expected values under each N are provided under the column labeled m^y . This approach is employed for all the models considered in this study and in Table 7 are the resulting GOFs for all the five distributions under case IV.
Table 7 gives the GOF for the five models (in comparison to the binomial model) and results here demonstrate that while the multiplicative binomial model is best, it is however not much better than the beta-binomial model. However, since the multiplicative model is not much difficult to model than the beta-binomial, it would be better to actually employ it. Our results in other studies regarding the two models suggest that the MBD may be a better choice. Clearly, both the BBD and the MBD show considerable improvements in model fits than the binomial model.
Our results here agree with those in Lindsey and Altham (1998) that the ”multi- plicative model fitted somewhat better than did the beta-binomial” [1]. Our procedure here estimates fewer parameters than those employed in Lindsey and Altham (1998) and the optimization techniques open to us with SAS PROC NLMIXED, makes the use of this procedure much easier to use [1]. The implementation and use of more models in this study gives a broader perspective on models used for data having binary outcomes, especially as are being applied to the Human Sex Ratio Data. The SAS programs employed for this analysis are available from the author.

![]()
|
|
|||||||||||||
|
||||||||||||||
Girls |
|
|
|
|
|
Boys |
|
|
|
|
|
|
|
|
|
n |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
F01 |
1 |
114609 |
108719 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
F02 |
2 |
47819 |
89213 |
42860 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
F03 |
3 |
20540 |
57179 |
53789 |
17395 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
F04 |
4 |
8628 |
31611 |
44793 |
28101 |
7004 |
- |
- |
- |
- |
- |
- |
- |
- |
F05 |
5 |
3666 |
16340 |
30175 |
28630 |
13740 |
2839 |
- |
- |
- |
- |
- |
- |
- |
F06 |
6 |
1579 |
7908 |
17332 |
22221 |
15700 |
6233 |
1096 |
- |
- |
- |
- |
- |
- |
F07 |
7 |
631 |
3725 |
9547 |
14479 |
13972 |
8171 |
2719 |
436 |
- |
- |
- |
- |
- |
F08 |
8 |
264 |
1655 |
4948 |
8498 |
10263 |
7603 |
3951 |
1152 |
161 |
- |
- |
- |
- |
F09 |
9 |
90 |
713 |
2418 |
4757 |
6436 |
5917 |
3895 |
1776 |
432 |
66 |
- |
- |
- |
F10 |
10 |
30 |
287 |
1027 |
2309 |
3470 |
3878 |
3072 |
1783 |
722 |
151 |
30 |
- |
- |
F11 |
11 |
24 |
93 |
492 |
1077 |
1801 |
2310 |
2161 |
1540 |
837 |
275 |
72 |
8 |
- |
F12 |
12 |
7 |
45 |
181 |
478 |
829 |
1112 |
1343 |
1033 |
670 |
286 |
104 |
24 |
3 |
Parameters |
I |
II |
III |
IV |
|
Beta-Binomial Model |
|||||
αˆ0 |
4.5817 (0.0362) |
5.3977 (0.1248) |
4.5826 (0.0362) |
5.3954 (0.1248) |
|
αˆ1 |
- |
-0.1100(0.0143) |
- |
-0.1096 (0.0143) |
|
ˆβ0 |
0.0600(0.0011) |
0.0599 (0.0011) |
0.0497 (0.0026) |
0.0498 (0.0026) |
|
|
|||||
ˆ |
- |
- |
0.0018 (0.0004) |
0.0018 (0.0004) |
|
|
|||||
-2LL |
4180.8 |
4118.6 |
4162.4 |
4100.8 |
|
X2 |
194.0652 |
126.3841 |
174.8058 |
108.4632 |
|
G2 |
187.6311 |
125.5495 |
169.2988 |
107.7504 |
|
Multiplicative Binomial Model |
|||||
αˆ0 |
-0.0196 (0.0007) |
-0.0055(0.0020) |
-0.0195(0.0007) |
-0.0058 (0.0020) |
|
αˆ1 |
- |
-0.0019 (0.0003) |
- |
-0.0019 (0.0003) |
|
ˆ |
0.0573(0.0011) |
0.0573(0.0011) |
-0.0507(0.0025) |
0.0522 (0.0025) |
|
β0 |
|
||||
ˆ |
- |
- |
0.0011(0.0004) |
0.0009 (0.0004) |
|
β1 |
|
||||
-2LL |
4159.4 |
4103.2 |
4151.2 |
4098.4 |
|
X2 |
171.3320 |
110.7833 |
162.8512 |
106.0609 |
|
G2 |
166.2496 |
110.1267 |
158.1647 |
105.3662 |
|
Double-Binomial Model |
|||||
αˆ0 |
-0.0318(0.0014) |
0.0256 (0.0032) |
-0.0317(0.0014) |
0.0256 (0.0032) |
|
αˆ1 |
- |
-0.0123 (0.0006) |
- |
-0.0123 (0.0006) |
|
ˆ |
0.0601 (0.0011) |
0.0598(0.001) |
0.0499 (0.0026) |
0.0498 (0.0026) |
|
|
|||||
ˆ |
- |
- |
0.0018 (0.0004) |
0.0018 (0.0004) |
|
|
|||||
-2LL |
4525.0 |
4143.4 |
4506.8 |
4125.6 |
|
X2 |
562.2668 |
152.0558 |
541.8158 |
133.5381 |
|
G2 |
531.9262 |
150.2028 |
513.7150 |
132.4454 |
|
Com-Poisson Binomial Model-CPM |
|||||
αˆ0 |
0.9477 (0.0021) |
1.0256(0.0050) |
0.9479 (0.0021) |
1.0247 (0.0051) |
|
αˆ1 |
- |
-0.0141 (0.0008) |
- |
-0.0140 (0.0006) |
|
ˆ |
1.0595 (0.0011) |
1.0589 (0.0011) |
1.0499 (0.0027) |
1.0533 (0.0027) |
|
|
|||||
ˆ |
- |
- |
0.0017 (0.0004) |
0.0010 (0.0004) |
|
|
|||||
-2LL |
4396.8 |
4110.8 |
4381.6 |
4105.6 |
|
X2 |
424.1706 |
118.6071 |
407.2423 |
113.1593 |
|
G2 |
403.7245 |
117.7763 |
388.4260 |
112.4623 |
|
Correlated Binomial Model-CBM |
|||||
αˆ0 |
0.0025 (0.0001) |
0.0005 (0.0003) |
0.0025 (0.0001) |
0.0497 (0.0026) |
|
αˆ1 |
- |
0.0003 (0.00004) |
- |
0.0018 (0.0004) |
|
ˆ |
0.0560 (0.0011) |
0.0599 (0.0011) |
0.0497 (0.0026) |
0.0005 (0.0003) |
|
|
|||||
ˆ |
- |
- |
0.0018 (0.0004) |
0.0003 (0.00004) |
|
|
|||||
-2LL |
4185.6 |
4123.8 |
4167.2 |
4105.8 |
|
X2 |
200.9393 |
133.6860 |
181.5540 |
115.5038 |
|
G2 |
192.5759 |
130.6794 |
174.1174 |
112.7036 |
|
πˆ |
0.5150 |
|
|
|
|
θ |
0.0025 |
|
|
|
|
Family |
|
|
πˆn |
|
|
BBD |
MBD |
DDM |
CPB |
CBM |
|
2 |
0.5133 |
0.5135 |
0.5133 |
0.5134 |
0.5133 |
3 |
0.5138 |
0.5139 |
0.5138 |
0.5137 |
0.5138 |
4 |
0.5142 |
0.5142 |
0.5142 |
0.5139 |
0.5142 |
5 |
0.5147 |
0.5146 |
0.5147 |
0.5141 |
0.5147 |
6 |
0.5151 |
0.5150 |
0.5151 |
0.5143 |
0.5151 |
7 |
0.5156 |
0.5154 |
0.5155 |
0.5146 |
0.5156 |
8 |
0.5160 |
0.5159 |
0.5160 |
0.5148 |
0.5160 |
9 |
0.5165 |
0.5165 |
0.5164 |
0.5150 |
0.5165 |
10 |
0.5169 |
0.5171 |
0.5169 |
0.5153 |
0.5169 |
11 |
0.5173 |
0.5177 |
0.5173 |
0.5155 |
0.5174 |
12 |
0.5178 |
0.5184 |
0.5177 |
0.5157 |
0.5178 |
n |
κn |
κn−1 |
κn−2 |
ˆ |
πˆ1 |
πˆ2 |
var |
ωˆn |
|
2 |
0.99526 |
0.99538 |
1.00000 |
0.51348 |
0.51354 |
0.26492 |
1.0295 |
0.99050 |
|
3 |
0.98313 |
0.98343 |
0.98905 |
0.51369 |
0.51385 |
0.26547 |
2.3422 |
0.98868 |
|
4 |
0.96124 |
0.96177 |
0.96838 |
0.51391 |
0.51419 |
0.26606 |
4.1919 |
0.98686 |
|
5 |
0.92770 |
0.92849 |
0.93603 |
0.51412 |
0.51456 |
0.26670 |
6.5829 |
0.98503 |
|
6 |
0.88132 |
0.88240 |
0.89076 |
0.51434 |
0.51497 |
0.26738 |
9.5200 |
0.98321 |
|
7 |
0.82189 |
0.82327 |
0.83227 |
0.51456 |
0.51542 |
0.26811 |
13.0090 |
0.98139 |
|
8 |
0.75033 |
0.75198 |
0.76141 |
0.51477 |
0.51591 |
0.26891 |
17.0567 |
0.97956 |
|
9 |
0.66872 |
0.67062 |
0.68020 |
0.51499 |
0.51645 |
0.26977 |
21.6707 |
0.97774 |
|
10 |
0.58022 |
0.58229 |
0.59173 |
0.51520 |
0.51705 |
0.27070 |
26.8602 |
0.97592 |
|
11 |
0.48876 |
0.49093 |
0.49992 |
0.51542 |
0.51771 |
0.27172 |
32.6362 |
0.97409 |
|
12 |
0.39862 |
0.40079 |
0.40907 |
0.51564 |
0.51844 |
0.27285 |
39.0116 |
0.97227 |
|
Family |
Dispersion Estimated Parameters |
|
||||
BB |
MBD |
DDM |
CPB |
CBM |
|
|
2 |
ωˆi |
ˆ |
νˆi |
ˆ |
|
|
|
||||||
2 |
0.0056 |
0.9905 |
1.0011 |
0.9968 |
0.0011 |
|
3 |
0.0063 |
0.9887 |
0.9889 |
0.9828 |
0.0014 |
|
4 |
0.0070 |
0.9869 |
0.9769 |
0.9688 |
0.0016 |
|
5 |
0.0078 |
0.9850 |
0.9650 |
0.9549 |
0.0019 |
|
6 |
0.0087 |
0.9832 |
0.9532 |
0.9409 |
0.0022 |
|
7 |
0.0097 |
0.9814 |
0.9416 |
0.9270 |
0.0025 |
|
8 |
0.0108 |
0.9796 |
0.9301 |
0.9130 |
0.0028 |
|
9 |
0.0120 |
0.9777 |
0.9188 |
0.8990 |
0.0030 |
|
10 |
0.0134 |
0.9759 |
0.9076 |
0.8851 |
0.0033 |
|
11 |
0.0149 |
0.9741 |
0.8966 |
0.8711 |
0.0036 |
|
12 |
0.0166 |
0.9723 |
0.8856 |
0.8572 |
0.0039 |
|
n |
y |
pˆy |
pˆy |
mˆy |
X 2 |
G2 |
ωˆn |
|
2 |
0 |
0.2378 |
P |
42783.3261 |
P |
P |
0.9905 |
|
|
|
|
0.2378 |
0.1374 |
153.4851 |
|
||
2 |
1 |
0.4973 |
0.7351 |
89453.4146 |
0.7835 |
-326.6974 |
0.9905 |
|
2 |
2 |
0.2649 |
1.0000 |
47655.2593 |
1.3462 |
1.3460 |
0.9905 |
|
3 |
0 |
0.1170 |
0.1170 |
17418.3948 |
1.3776 |
-45.4121 |
0.9887 |
|
3 |
1 |
0.3624 |
0.4793 |
53957.9978 |
1.9069 |
-382.8778 |
0.9887 |
|
3 |
2 |
0.3828 |
0.8621 |
56996.6365 |
2.4904 |
-17.5679 |
0.9887 |
|
3 |
3 |
0.1379 |
1.0000 |
20529.9709 |
2.4953 |
2.4951 |
0.9887 |
|
4 |
0 |
0.0581 |
0.0581 |
6977.4982 |
2.5959 |
55.5992 |
0.9869 |
|
4 |
1 |
0.2361 |
0.2941 |
28359.9063 |
4.9596 |
-459.8425 |
0.9869 |
|
4 |
2 |
0.3694 |
0.6636 |
44383.7008 |
8.7340 |
362.5188 |
0.9869 |
|
4 |
3 |
0.2639 |
0.9274 |
31698.7478 |
8.9769 |
187.2663 |
0.9869 |
|
4 |
4 |
0.0726 |
1.0000 |
8717.1469 |
9.8886 |
9.8873 |
0.9869 |
|
. |
. |
. |
. |
. |
. |
. |
. |
|
. |
. |
. |
. |
. |
. |
. |
. |
|
. |
. |
. |
. |
. |
. |
. |
. |
|
12 |
0 |
0.0004 |
0.0004 |
2.5561 |
90.9736 |
91.2014 |
0.9723 |
|
12 |
1 |
0.0039 |
0.0043 |
23.9718 |
90.9736 |
91.2578 |
0.9723 |
|
12 |
2 |
0.0178 |
0.0222 |
108.9954 |
91.2026 |
81.4994 |
0.9723 |
|
12 |
3 |
0.0520 |
0.0741 |
317.7147 |
94.3684 |
21.3468 |
0.9723 |
|
12 |
4 |
0.1081 |
0.1823 |
661.2655 |
94.4838 |
38.9307 |
0.9723 |
|
12 |
5 |
0.1693 |
0.3516 |
1035.2798 |
94.4888 |
34.3761 |
0.9723 |
|
12 |
6 |
0.2044 |
0.5560 |
1250.1793 |
101.3803 |
226.7445 |
0.9723 |
|
12 |
7 |
0.1919 |
0.7479 |
1173.2732 |
104.5803 |
107.4552 |
0.9723 |
|
12 |
8 |
0.1389 |
0.8868 |
849.2952 |
105.0653 |
67.3537 |
0.9723 |
|
12 |
9 |
0.0756 |
0.9624 |
462.4465 |
105.5884 |
98.9780 |
0.9723 |
|
12 |
10 |
0.0294 |
0.9918 |
179.7935 |
105.5965 |
101.3991 |
0.9723 |
|
12 |
11 |
0.0073 |
0.9991 |
44.8135 |
105.5973 |
101.7729 |
0.9723 |
|
12 |
12 |
0.0009 |
1.0000 |
5.4154 |
106.0609 |
105.3662 |
0.9723 |
|
12 |
12 |
0.0009 |
1.0000 |
5.4154 |
106.0609 |
105.3662 |
0.9723 |
|
Model |
d.f |
G2 |
X 2 |
Binomial |
85 |
3551.857 |
3807.590 |
Beta-B |
83 |
107.7504 |
108.4632 |
MBM |
83 |
105.3662 |
106.0609 |
DBM |
83 |
132.4454 |
133.5381 |
Com-PB |
83 |
112.4623 |
113.1593 |
CBM |
83 |
112.7036 |
115.5038 |




































